Predicting the Fare on a Billion Taxi Trips with BigQuery
How long time does it take and how much does it cost to analyse and train a model on a billion taxi trips in the cloud? When do most trips occur, what affects the total fare amount the most and how accurately can we predict it?
Google's BigQuery makes it straight forward to analyse the data before applying machine learning to it. We will use the publicly available cab rides dataset for New York City, which includes over 1.1 billion rides between 2009 and 2015. Due to the size of the dataset, we will initially work on a small fraction of it to facilitate visualisation and save on query costs. Once developed a good understanding of the data we'll train a model on all 1 billion samples. Lastly, we will use the model to make predictions before analysing the errors.
I will mainly work in a Jupyter notebook environment hosted on Google Cloud Platform to facilitate the documentation of each step. The complete notebook with more details can be accessed on GitHub.

Exploratory Data Analysis
Start by querying 1 in 10,000 rows of the data using BigQuery, keeping a subset of the columns only. Since the dataset consist of a little more than 1 billion records, we will end up with just north of 100,000 rows. This size will be small enough to facilitate data visualisation while large enough to represent the entire dataset pretty well. This is how the query looks like:
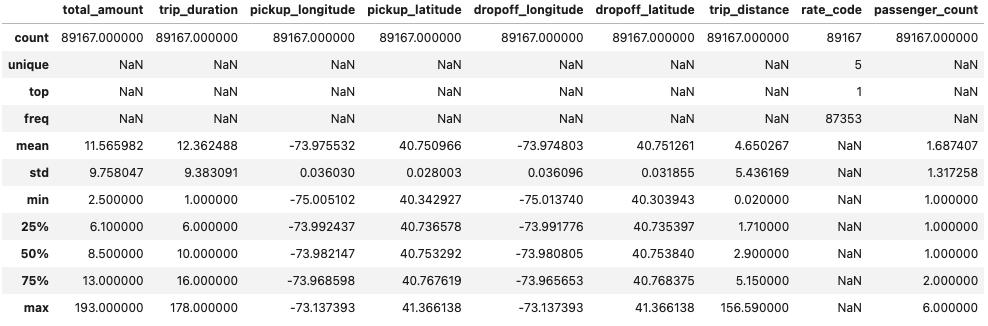
We can now calculate some descriptive statistics to get a better understanding of the data.
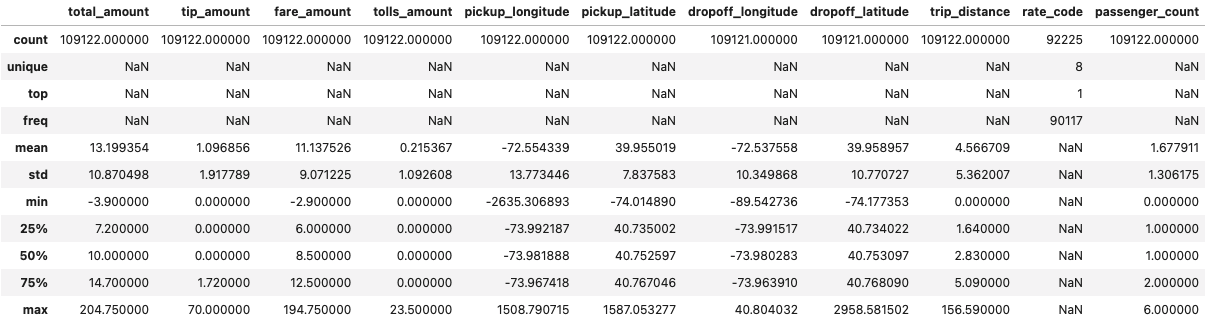
Among other things, we learn the following
- The subset we're currently working with include 109,122 trips.
- There are questionable high and low values in pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude.
- rate_code is missing in over 15,000 trips (92,225 are present).
- There are zero distance trips.
- There are negative values in fare_amount and total_amount.
- The average total_amount is $13.2
Let's move forward by extracting hour, day, month and year from the pickup_time column as well as calculating trip duration to facilitate further analysis.
Categorical Variables
Now when we have an overall understanding of the data, we can dig a little deeper into each one of the columns.
Columns passenger_count, pickup_hour, day_of_week, pickup_month and pickup_year are all discrete ordinal variables (i.e., there is a natural ordering of the values where 14:00 comes before 15:00, and so forth). In terms of rate_code however, there is no such interrelationship between, for example, group 1 (standard fare) and 2 (JFK); it makes little sense to say that standard fare comes before an airport fare.

Some takeaways from above plot:
- Over 80% of the trips use standard rate (1). (2) and (3) refers to JFK and Newark, respectively. Although surprisingly low airport counts, we can keep them. Rate code (6), group ride, can be excluded since the same information is mapped in the passenger_count column. As identified before, there are over 15,000 rows missing in this column. Although there are several ways we can approach this, we will go with the easiest solution which is excluding rows with missing values. We include rate codes 1–5 only.
- 70% of the trips have only one passenger while there are trips with zero passengers. It's unreasonable to charge for trips with no passengers and we'll therefore exclude those trips. Additionally, we can limit the variable to a maximum of 6 passengers to be on the safe side.
- The busies pickup hours are in the late afternoon throughout late evening. However, it's fairly consistent between 11:00 and 22:59 with some occasional dips around 13 and 16. The least busy hours are early mornings from 03:00 to 05:59. This seem reasonable and maps well with working hours.
- The busiest days of the week are Thursdays and Fridays. But it's fairly consistent with little more than 10% difference between Sunday lows and Friday peaks.
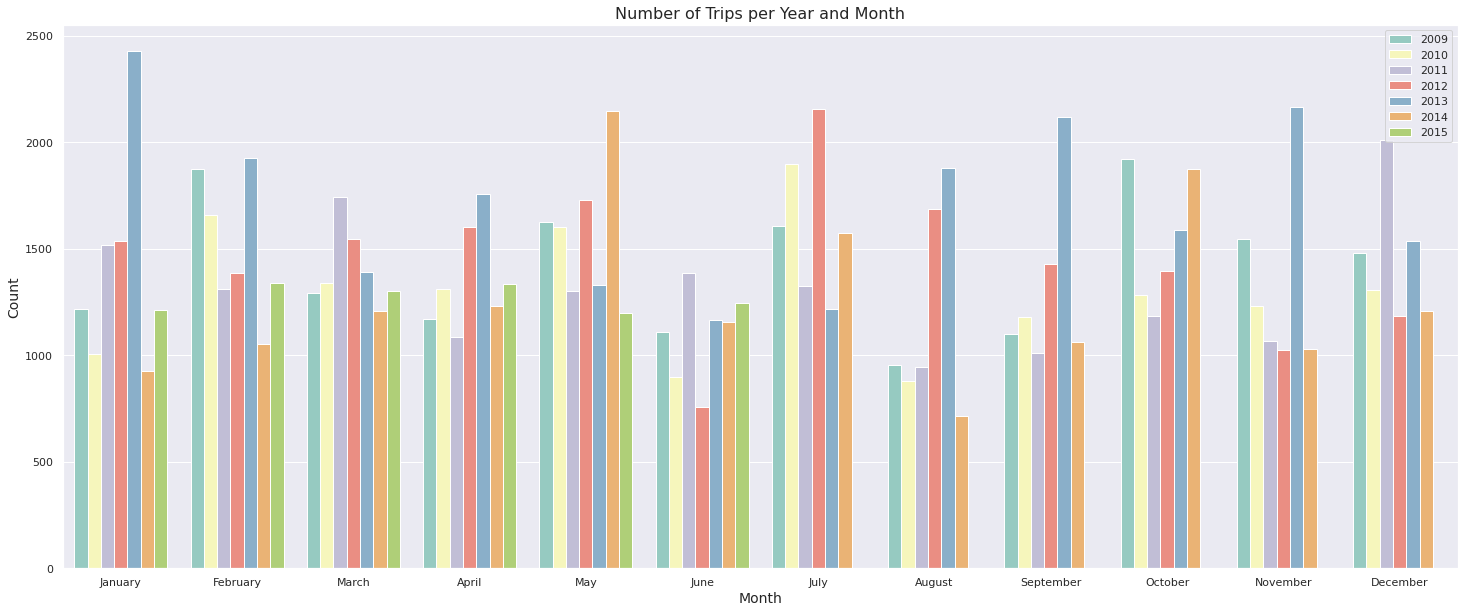
- Averaged over all years, May, July and October seem to be the busiest months, while June and August are least busy. This seem to hold true even if we additionally split it up by month as shown below.
- Most trips are registered during 2013 while fewest in 2015. However, as displayed more clearly below, 2015 contain only trips during the first six months of the year (light green bar).
Continuous Variables
Next up, we will take a closer look at the continuous variables by plotting them using histograms.

Among other things, we learn the following from above plots:
- total_amount includes negative values, which is rather counterintuitive. See below for how we approach this.
- Around 55% of the trips have zero tip. $1 and $2 tip amounts are the most common when tip is given. However, due to its nature of being a decision made by the rider, we will exclude this column and calculate total_amount as fare_amount + tolls_amount.
- There are negative values in fare_amount. We exclude all values that are zero or lower and set the upper threshold at $500.
- Most trips (96%) don't include tolls. We can limit tolls_amount to the range [0, 25].

- Some long trips (>100km) have unreasonable low total fare amount (<$10) with questionable trip duration. Let's exclude those. We can also set a restriction to only include trips below 160km to assure we stay within the city area.
- There are many trips that have zero or negative trip_duration (521 in total), while others are taking very long time. Some are as long as almost 24 hours. I'm displaying trips that take more than 3 hours (180 min) below. Most of them are shorter than 5km. Perhaps they got stuck in traffic, but it's doubtful whether anyone would be stuck for nearly 24 hours. Although it's not unreasonable for taxi rides to take many hours (perhaps someone took one to Chicago), we will focus on trips in the closer vicinity of NY City and will thus exclude these data points. We'll specify the acceptable range to [0, 180].

Calculate Correlation between Features and Total Trip Amount
To better understand the relationship between the target variable and the features in the dataset, we will calculate Pearson correlation among the columns and display the result in something referred to as a correlation matrix.
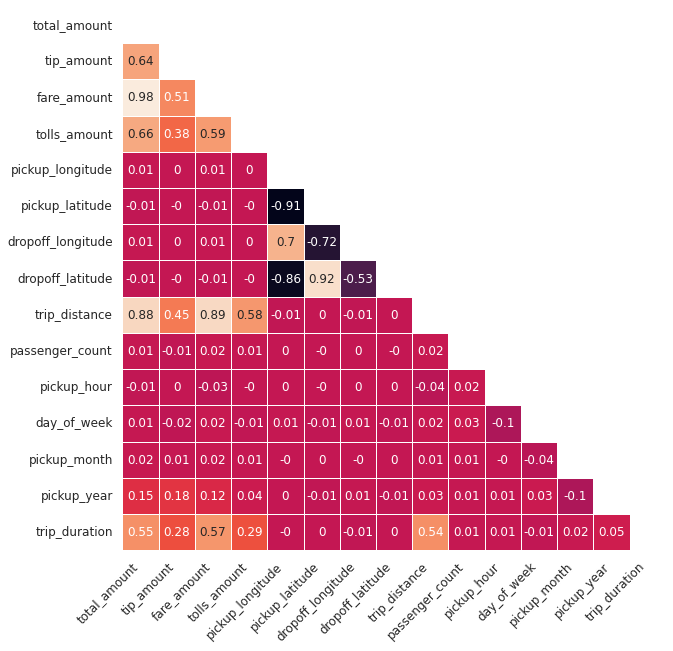
- We note that total_amount is highly correlated with fare_amount, trip_distance, tolls_amount, tip_amount and trip_duration. This seems reasonable as we would expect longer trips, both in time and distance, to cost more.
- There is a weak correlation with pickup_year. This also seems fairly reasonable as we can expect fares to change slightly over time.
- The correlation is negligible for most other features such as pickup and drop-off coordinates. In isolation, this is reasonable. However, when combining longitude and latitude to form the exact pickup and drop-off locations we would expect this to affect the total fare. Above correlation matrix is unable to calculate pairwise correlations though and we would have to engineer this relationship ourselves. We will do this in a later step. Depending on how the taxi company sets its pricing, we would perhaps also expect pickup_hour to affect the fare amount more (rides might be more expensive during peak hours for example).
Display Pickup and Drop-off Locations on a Map
Plot the pickup and drop-off locations over a map of NY City to get a better understanding of their location.
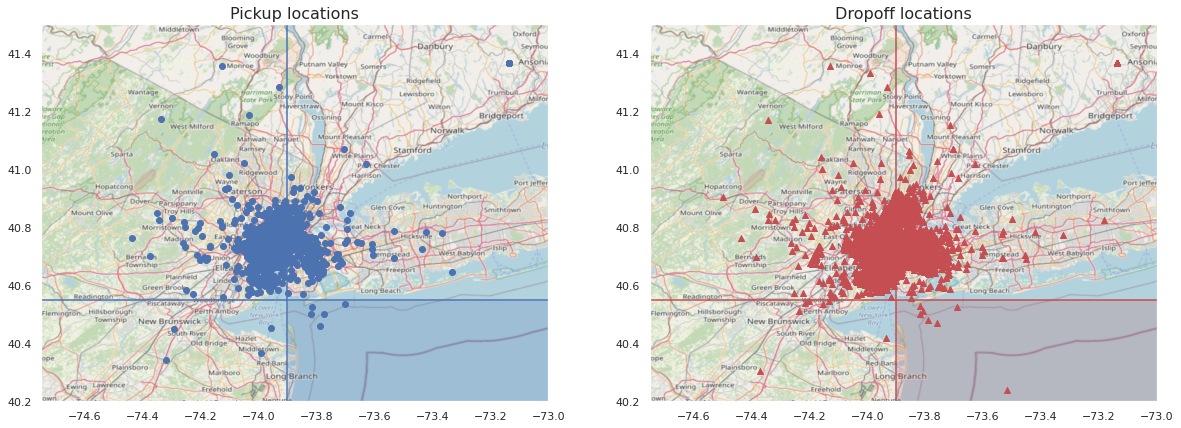
We can confirm that most trips are concentrated within the city area.
However, there are also seemingly erroneous data points with pickup and/or drop-off locations in the ocean. One way to approach this is to exclude trips that are below latitude 40.55 while at the same time located east of longitude -73.9 (blue and red shaded areas). We can specify overall latitude limits to [40, 42] and longitudes to [-76, -73]. This also excludes some unreasonably high (pickup coordinates above 1,500) and low (pickup longitudes at -2,600 and 0) coordinates which were identified before.
Machine Learning with BigQuery ML
Now comes the most exciting part; applying machine learning to make predictions on the total fare amount. To save on development costs and to speed things up, we will approach this as before; starting out with a smaller dataset for experimentation, and once a satisfying result is achieved, we train a model on the entire dataset. Although much of it can be completely automated in BigQuery, we will take it step by step as it will be easier to follow along.
BigQuery makes it simple to apply a variety of different models on the data. Although it's best practice to experiment with several different models, for the purpose of this article, we will go with Linear Regression only. Even though there are differences in data preparation and hyperparameters between the models, the general steps are common. Linear Regression is fast to train but requires more work in order to map the interrelationship between features for best performance. We will cover this in more depth in model 4 below.
We can set the baseline to beat at $9.8, which is equivalent to the standard deviation. However, we want to be a little more ambitious than that and will set the goal to below $3.
Goal: Below $3.
Create Data Table for Machine Learning and Exclude Irrelevant Values
Based on what we've learned from the exploratory data analysis earlier, we can now go ahead and create a training data table. We will also make sure to order the data by dropoff_time. This way we'll be making predictions on future trips which is more similar to a real-world setting. There's also the risk of trips on the same day being correlated due to traffic conditions and so forth. Ordering by date might help to mitigate this. The query for creating a data table using the constraints we decided during the EDA while keeping the data size as before looks as follows:
Before moving on, we'll confirm that all values are within acceptable range.
Model 1: Three Features only
We will start out humbly by only including three features:
- trip_distance
- rate_code
- passenger_count
The target variable is the total trip amount, total_amount while we will be using dropoff_time to split the data sequentially to maintain trip date ordering. BigQuery splits the data for us automatically into train and evaluation sets so we don't have to worry about that.
We use the following SQL to evaluate the model on the train set.
And the following to evaluate it on the test set.
We get an RMSE of 3.34 on the test set and 3.26 on the train set on the first attempt - significantly better than the 9.8 baseline and pretty close to the goal of 3.0! BigQuery also provides us with other evaluation metrics by default as well as the possibility to completely customise them. However, RMSE has the advantage of providing the error in the unit being measured (which is USD in this case) and is thus easier for the human eye to interpret.
Models 2-4
Equivalent steps are taken for models 2–4 where we add the following features:
Model 2:
- trip_distance
- rate_code
- passenger_count
- trip_duration
- pickup_longitude and pickup_latitude
- dropoff_longitude and dropoff_latitude
Model 3: Extract hour, weekday, month and year from the pickup_datetime column:
- pickup_hour: Pickup hour during the day for the trip (24 hours)
- pickup_day : Pickup day in the week (Monday - Sunday)
- pickup_month : Pickup month (January - December)
- pickup_year: Pickup year (2009 - 2015)
Unlike when we extracted weekday with Pandas, where the week started with Monday, BigQuery's DAYOFWEEK assumes Sunday to be the start of the week. However, for the purpose of this analysis, it shouldn't make a difference.
Model 4: Engineer new features by combining two or more current features into new ones. The idea is to better map the information within the data so that the model can better learn from it. However, this comes with an additional risk of overfitting and subsequent model performance decline if not addressed.
- euclidean: Calculate the shortest distance between two points on the map.
- day_hour: A combination of weekday and hour to map the hour in the week. Mornings during the week might have other characteristics, such as being busier, than mornings during the weekend, for example.
- month_hour: A combination of month and hour to map the hour in a month for the trip.
This leads us to the following query for model 4:
The additional features allow the model to fit the data a little better, yielding an RMSE of 2.27 on the test set and 2.38 on the train set.
Model 5: Although the model is not overfitting much, we can experiment with regularisation to see if we can push the test RMSE closer to the train RMSE. It's a common approach and there are two main ways to do that with Linear Regression; L1 and L2. We won't go into the details of how they work other than mentioning that L1 decreases (and even removes) the importance of the least important features, while L2 shrinks the importance of all features. The degree to how much this is done can be tuned and is specific for each use case and dataset.
For the purpose of this blog post we will focus on L1 and experiment with values [0, 0.1, 1, 10]. Executing it in parallel will speed things up. BigQuery splits the data into 80:10:10 train-evaluate-test sets by default during hyperparameter tuning and we won't interfere with that. The model is trained on the train set before evaluated on the evaluation set during each one of the four runs (four because we will evaluate four values of L1). Lastly, the final model performance is calculated by testing it on the test set which the model hasn't seen before. All this is done automatically by BigQuery.
By wrapping the features within the TRANSFORM clause we ensure that the same pre-processing steps taken during training are applied during evaluation and model deployment. Applying all the steps from above, this is how the query looks like:
No regularisation (L1 = 0.0) results in the best model with an RMSE on the test set of 2.33 and 2.22 on the evaluation set (see below). Note that since the data has been split into three sets during the hyperparameter tuning process, rather than previously two, the results are not exactly the same as for model 4 even though the regularisation parameter hasn't changed.


Train on All the Data
We've found the most optimal set of hyperparameters, engineered extra features, saved both time and money on the small dataset and can now move forward by training on the full, 1 billion trips, dataset.
To start, query the original dataset to create a new table including all the rows while still applying the same constraints as before.
Before initiating model training, verify that the columns are all within expected values.
Which gives us the following result.
Final Model
We are pretty pleased with these insights and can now move forward with model training on the full data. The query looks almost identical to the one we used for model 5, with the only difference being the data source we're querying from at the very bottom. I will thus not write out the entire query again but instead refer to the GitHub repo where all steps are present.
Training the model on 1 billion trips takes around 21 minutes at a cost of less than $20.
Training the model on 1 billion trips takes around 21 minutes at a cost of less than $20. We end up with a final RMSE on the train set of 2.36 and 2.59 on the test set. This is a little worse than what we achieved with model 5 which was trained on only 100k samples. There are some minor indications of overfitting (because the RMSE discrepancy between the train and test sets has increased) and perhaps adding regularisation when training on the full dataset would be beneficial after all. We won't iterate on that here other than pointing it out.
A summary on the train and test sets of all the models we've trained is found below. The best performance is achieved with models 3 and 4, taking into account that they were only trained on a subset of the data. We note the slight increase in overfitting on the final model.

Model Prediction and Analysis
What purpose has a model if we don't use it to make predictions with? Query 1 million samples and use the model to make predictions on them. Also, calculate the prediction errors by taking the difference between the prediction and the true label. The query looks like this:
We can then display the prediction error distribution and perform some basic analysis on the model performance.

95% of the prediction errors are lower than ±2.5 USD, which is in line with the RMSE on the test set. However, there are some predictions that are off by more than $100 in both directions as displayed below.

Let's take a closer look at some of those:
- Trip #27411 (see above): This trip is labelled with a total trip amount of $0.02 despite taking almost 2 hours (112 min) at a distance of 90km. It's weird. The data thus seem to be inaccurate in one way or another which could then explain the $173 prediction error.
- Trip #33913: A very low total fare amount ($9) despite long in both duration and distance. We might have a data issue here as well.
- Trip #10087 This is the trip with the largest (underestimated) error at -$321. The labelled total amount is $495. It might be an accurate data point since it's marked as a negotiated fare (rate_code = 5), meaning that the driver and rider agreed on a fare. Perhaps the rider was in a hurry and also needed to make some errands along the way and was happy to pay a premium for this. However, both the trip distance and duration are very similar to that of trip #27411 so it's not unreasonable to think that they should have roughly the same price. Not 3 times more. The model certainly estimates along these lines as well.
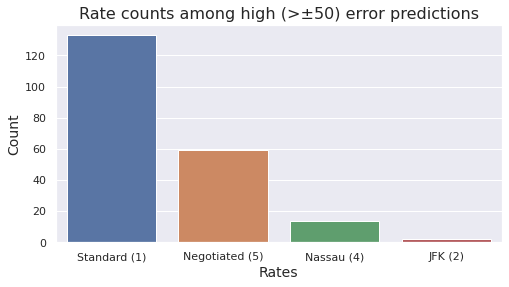
Negotiated fare is highly overrepresented with almost 30% of the trips (see the plot below) among trips with large errors. This is in large contrast to the general distribution of the dataset where negotiated fares make up only 0.2%. Perhaps negotiated fares are more random or have some other characteristics that makes them harder to predict. We should find ways of better mapping this if we want to improve model performance in the extremes.
There are thus several data points where we can question the validity of the data. Perhaps it's not the model that's doing bad but poor data that's behind the large prediction errors we experience on at least some of these trips.
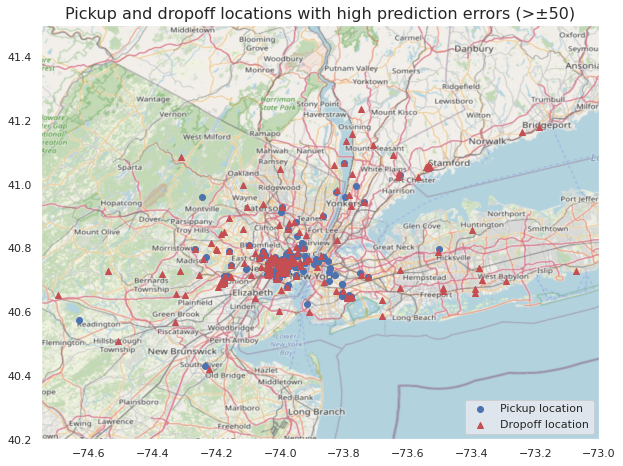
We can also verify that most trips take place within, or very close to New York and its vicinity by plotting them on a map. This way we can visually confirm that most of them are of shorter distance.
Summary
We've used BigQuery to load a dataset containing over 1 billion samples, visualised it and trained some models to predict the total taxi ride fare. We started with a smaller fraction of the dataset to better being able to visualise it and to save on query and model iteration costs. We also confirmed our intuition that trip distance and duration are highly correlated with the total fare amount, and showed that training the model on the entire dataset took no longer than 21 minutes at a cost of less than $20. Lastly, we also explored the prediction errors and their characteristics where we probably found additional data inaccuracies.
Although the article ended up longer than I first expected, there are many more potential paths to explore. Adding other external data sources such as weather conditions or events (e.g., festivals, holidays) may help boost the model performance, as can engineering more features to better map the total fare. We spent very little time tuning the hyperparameters which may add important improvements. Additionally, there's room for significantly more analysis in terms of better interpreting and understanding the results.
Only Linear Regression was used because it's comparably very fast to train. But there are more models to choose from (many of them available through BigQuery ML), some of which likely can decrease the error. In fact, I did a quick check with XGBoost on the smaller dataset and it decreased the error by around 25% off-the-shelf. It came with the drawback of taking around 10 times longer to train though.